Epischema – Schema Constraints That Facilitate Content Completion
April 29, 2017
The author’s XML Prague 2017 epischema paper was about adding content-specific grammars to the notoriously generic TEI structural divisions, thereby enabling both validity constraints and content completion. This article extends this concept to a real-life HTML use case.
Dave Cramer recently made a case for using HTML as a base format for integrated print/e-book publishing workflows. Other publishers such as O’Reilly are also adopting HTML-based authoring and production.
Apart from its lack of idiosyncratic publishing features such as footnotes, bibliographic references, or index terms, HTML’s major drawback is that it is way too permissive for publishing workflows. This is a drawback that it shares with word processor and DTP formats — for automatic conversion tools to generate the formats consistently, or for CSS to effect the desired layout, certain conventions as to the document structure and the use of class attribute values need to be established and respected.
There are several approaches to creating a more prescriptive HTML editing environment:
- For schema-aware XML editors, one can use a restricted schema that only allows creating a subset of HTML. This is the approach that HTMLBook pursues.
- If the XML editor supports it, the constraints can be supplied as an additional Schematron schema. Authors can enter anything that the base schema allows, risking that some of their input might then be flagged as illegal by the Schematron rules.
- The editing environment can be customized so that it only allows content to be entered that will be valid with respect to the constrained HTML.
Alternative 1: Create a constrained schema
A prerequisite for approach 1 is that the chosen schema language
supports context-dependent content models for elements with the same
name. It might be necessary to disallow arbitrary paragraph classes in
bibliographies, or to allow h1 headings only in heading
sections of a book’s primary structural units. These requirements rule
out DTD as schema language. But also for XSD or Relax NG, this
approach is generally difficult to implement. The reason is that, as
Eric van der Vlist explains in his excellent Relax NG book, schemas need to be
designed from the outset to allow restricted content models
(or attribute value spaces) at a given context in the future. It is
next to impossible for a schema designer to anticipate all the
constraints that people will apply to their generic schemas. Consider
that each context- or co-occurrence-dependent constraint on paragraphs will
necessitate a fork of the basic paragraph schema — either the attribute
values, the content model, or both. This is because the design of
(grammar-implementing) schema languages happens to support extensions
better than reductions.
In addition, one should not even need to know the inner building blocks and the wiring of a given schema. One should be able to treat it as a black box and add the constraints on top, just like Schematron allows it.
Example: Some time ago, you saved an XHTML 1.0 DTD as Relax NG in order to be able to add context-dependent restrictions. Now you want to migrate your workflow to (X)HTML5 while keeping most the restrictions unchanged. It turns out that although most documents are valid against either base schema, you’ll have to rewrite most of your constraints. This is because the schemas don’t use the same internal building blocks.
This base schema opacity requirement rules out approaches where a derived constraining schema is generated from a (maybe annotated) source schema via XSLT or other means. This approach frequently requires that someone provides customizable building blocks in the required granularity. In any case, it requires knowledge of the internal models used in the schema. We’d prefer a mechanism, like Schematron, in which we don’t even have to bother in which schema language the base schema is written.
Alternative 2: Add Schematron constraints
So what keeps us from using Schematron rules for the constraints? Content completion it is. Since in Schematron, both context selectors and assertions may hold almost arbitrary XPath expressions, it is next to impossible to calculate a finite list of class attributes that are permitted at a given location. The case is certainly easier if you were to restrict a content model that allowed a finite set of alternatives in the first place. But still, it would be quite costly to pre-evaluate the Schematron assertions against any combination of content elements or attribute values that the base schema allows in a given context. It is even impossible for attributes that enjoy an open-ended value space in the base schema.
Alternative 3: Constrain the editing environment
Restricting an author’s freedom in an XML editor (Web-based or standalone application), if not done by a schema, can be effected by editor-specific customization mechanisms, including programming language code. These mechanisms are less portable than any of the declarative, standards-compliant schema or assertion language variants.
In order to support “write once, use anywhere” for content rules, editing tool vendors should really look into utilizing standardized languages for configuration, also for things beyond content completion. CSS is certainly another standardized, declarative language for this. Other aspects, such as which complex widget to use in order to render a chunk of content, might still be vendor-specific. But it’s worth the while to try to make this configuration at least declarative, for example as annotations in one of the Relax NG schemas.
A blissful synthesis
We are now presenting a mechanism for restricting base grammars, called epischema (ἐπί = on top of, i.e., an additional lightweight schema on top of a base schema), that gives us the best features of all approaches:
- It is orthogonal and base-schema agnostic like Schematron;
- It provides context-aware content completion that respects co-occurrence constraints;
- An epischema (in conjunction with the base schema) is all that is needed in order to configure content completion.
An epischema is a Relax NG schema (XSD 1.1 might also be possible) that is sparse in that it does not specify the full document grammar. Its core component is an almost anything pattern that permits any element and any attribute anywhere—except for certain elements/attributes that have specialized models or are outright forbidden, globally or in certain contexts. The document is validated twice: Once against the base schema, once against the epischema. Only those elements and attributes pass the combined validation that are permitted by both schemas.
A couple of things should be noted: 1. While epischemas can only be
expressed in schema languages that allow co-occurrence constraints and
“anything except …” patterns, the base schema does not necessarily
have to be a Relax NG schema. It may, in principle, also be a DTD, XSD, or a Schematron
schema (although you might have to convert DTD and
XSD to Relax NG first, which is almost always possible.). 2. “Both schemas” is misleading as there is no limit to the
number of epischemas associated with a document. Each epischema can
constrain different aspects such as the document structure or
bibliography tagging. 3. Epischemas are subject to the standard Relax
NG extension mechanisms. We will study below an epischema that
specifies a book document structure by providing a grammar for
div elements with certain @class
attributes. This epischema may be extended so that it also allows
journal article documents besides books.
How does it work in practice?
Before we illustrate how to design an epischema, we will demonstrate two alternative ways to associate an existing epischema with a document.
<?xml-model?> schema association
A common way to associate multiple schemas with a document is to use multiple xml-model processing instructions. This is
seen frequently when a Relax NG schema contains embedded Schematron rules. TEI and DocBook schemas usually come with additional Schematron constraints. Here is a typical TEI schema/schematron association:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-model
href="http://www.tei-c.org/release/xml/tei/custom/schema/relaxng/tei_all.rng"
schematypens="http://relaxng.org/ns/structure/1.0"?>
<?xml-model
href="http://www.tei-c.org/release/xml/tei/custom/schema/relaxng/tei_all.rng"
schematypens="http://purl.oclc.org/dsdl/schematron"?>
<TEI xmlns="http://www.tei-c.org/ns/1.0">
<teiHeader>
…
XML editors such as oXygen will take these processing instructions into account and validate against both associated schemas while you type.
The same mechanism can be used for associating two or more Relax NG schemas. Our sample document (Moby Dick, kindly provided by Dave Cramer without schema associations) features two Relax NG schema associations:
<?xml-model
href="http://www.idpf.org/epub/30/schema/epub-xhtml-30.rnc"
type="application/relax-ng-compact-syntax"?>
<?xml-model
href="https://subversion.le-tex.de/common/schema/FoundationXHTML-Epischema/schema/fx-html-ns.rnc"
type="application/relax-ng-compact-syntax"?>
…
As a side note: Both schemas happen to be in Relax NG compact syntax, but either of them could also be a Relax NG XML syntax file.
The rules that the second schema provides implement constraints that are laid out in IGP’s Foundation XHTML (short: FX) specification, in particular:
- document structure (a flat sequence of divs, with class attributes signaling each div’s location in the document hierarchy);
- detailed constrained models, such as:
- heading blocks must contain
h1, whileh1is forbidden outside of heading blocks; - the JATS grammar for
mixed-citationand sub-elements such asstring-name, implemented with HTMLspans whose class attributes match the corresponding JATS element names;
- heading blocks must contain
- disallowing elements altogether that are allowed in standard HTML.
Example: The small element fell prey to such a global ban in FX. Its use in Moby Dick will be flagged in oXygen:
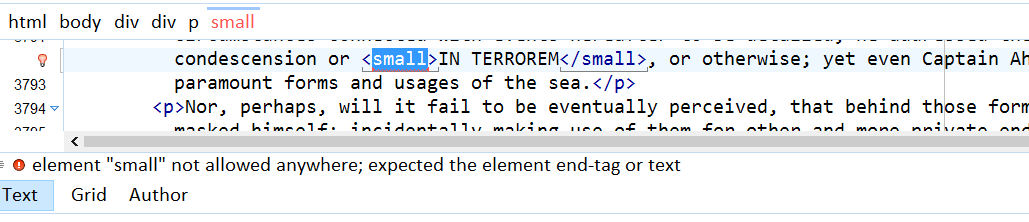
In orthodox FX, the content should probably be expressed as span.uppercase-rw that might entail, as a byproduct, the typographic effect of rendering uppercase text a bit smaller.
We saw that the additional schema will already be used for validation. But will it also offer content completion? As for oXygen, the answer is: not yet, not if associated by xml-model. This is because oXygen’s content completion, as of April, 2017, only uses the first xml-model association. This is a shortcoming that is likely to be fixed in the version that comes after 19.0.
NVDL Schema association
Fortunately, there is a workaround: Use NVDL instead of xml-model:
<rules xmlns="http://purl.oclc.org/dsdl/nvdl/ns/structure/1.0"
xmlns:a="http://relaxng.org/ns/compatibility/annotations/1.0" startMode="default">
<mode name="default">
<namespace ns="http://www.w3.org/1999/xhtml">
<validate schemaType="application/relax-ng-compact-syntax"
schema="http://www.idpf.org/epub/30/schema/epub-xhtml-30.rnc"/>
<validate schemaType="application/relax-ng-compact-syntax"
schema="fx-html-ns.rnc" useMode="allow"/>
</namespace>
</mode>
<mode name="allow">
<anyNamespace>
<allow/>
</anyNamespace>
</mode>
</rules>
In terms of validation, this single NVDL has the same effect as the two Relax NG xml-model processing instructions: The whole document must be valid against both Relax NG schemas.
In terms of content completion, oXygen up to version 18.1 did the following: If each of the schemas provided a list of elements or attributes that are valid at a given point, it would offer the union of both lists. The correct behavior would be to offer an intersection, since the suggested items must be valid against both schemas at once. This has been fixed in the recently released version 19.0.
Example: Title blocks
With this fix, the constraints within a chapter’s div.title-block-rw require us to insert an h1 element and only allow very few other elements there:
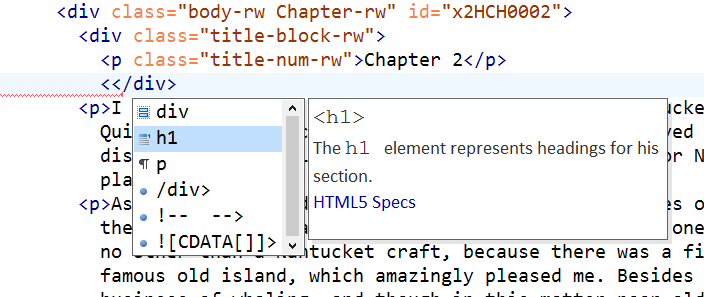
Note that neither need these constraints be retrofitted into the base schema nor need the additional schema specify a detailed content models for the, say, h1 element. They are declared in the lightweight,
complementary epischema.
In Relax NG compact syntax, the content model for div.title-block-rw looks like:
fx-title-block =
element div {
fx-non-class-atts,
attribute class {
list { "title-block-rw", fx-other-class* }
},
(h1 & (fx-title-num | fx-title-other | fx-title-author
| fx-title-sub | fx-title-epigraph)*)
}
The epischema definition of h1 does not provide a model for its inner markup — specifying this is totally up to the base schema. In the epischema, the h1 model is very generic:
h1 =
element h1 {
fx-any-atts,
fx-anymixed
}
with
fx-anymixed =
(text | fx-anything | fx-span)*
and
fx-anything =
element * - (# There are context-dependent models for these elements:
body | div | h1 | p | span |
# Deprecated phrases, see
# http://apex.infogridpacific.com/fx/fx03-inline.html#h365:
cite | code | command | dfn | em | embed | kbd | keygen |
mark | meter | output | progress | q | ruby | samp | small |
strong | time | var | wbr |
# I think it was mentioned somewhere that the HTML5 section
# and article elements are deprecated, too:
section | article
){
fx-any-atts,
(text
| fx-body
| fx-anymixed)*
}
| fx-block
| fx-dialog
| fx-p
This fx-anything pattern is the core pattern of the epischema approach. It basically says that any element is allowed anywhere, with a few significant exceptions for which context-dependent models exist.
To understand this approach, imagine you as a validator are applying the epischema to a document. You start with the document element, html. This top-level element must match the start pattern, fx-anything:
start = fx-anything
Since html is not in the exception list element * - (…), it is permitted by fx-anything. Whether html is really valid here depends on whether its content matches the element * - (…) {text | fx-body | fx-anymixed} part of fx-anything.
Of the two html children that are permitted by the base schema, namely head and body, the head element and its children also satisfy the fx-anything pattern. That means they also satisfy the fx-anymixed pattern since it contains fx-anything as a choice alternative. Therefore the whole head subtree is valid in html.
body is a different thing. It is excluded from the name wildcard in fx-anything so the validator (you) might initially think it is not permitted. But fx-anything allows a pattern named fx-body in each fx-anything-matching element. (Note that only the base schema’s rules will disallow body in all kinds of random places.)
fx-body =
element body {
fx-any-atts,
fx-galley
}
The fx-body pattern requires that the nodes in the body element satisfy the fx-galley pattern — a div element with a mandatory class, galley-rw:
fx-galley =
element div {
fx-non-class-atts,
attribute class {
list { "galley-rw", fx-other-class* }
},
fx-metadata*,
fx-frontmatter,
fx-bodymatter,
fx-backmatter,
fx-processor*
}
It may have other classes (space-separated tokens) in the class attribute, provided that they don’t end in -rw. The suffix -rw represents Foundation XHTML’s namespace for reserved classes.
fx-other-class =
xsd:token { pattern = "..?.?|.+[^\-][^r][^w]" }
Let’s continue to look at how the epischema guides the author while they are completing the chapter title block:
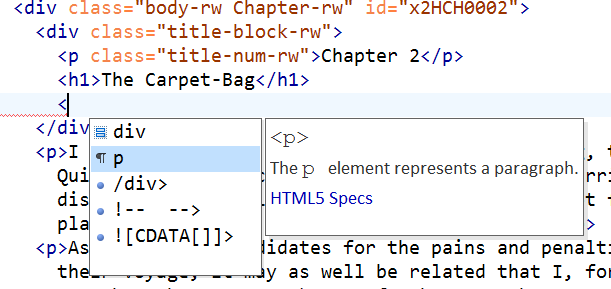
Once h1 has been inserted, only p or div elements are allowed (at least before we reluctantly introduced the more liberal schema that is described in the box above).

p needs a class attribute
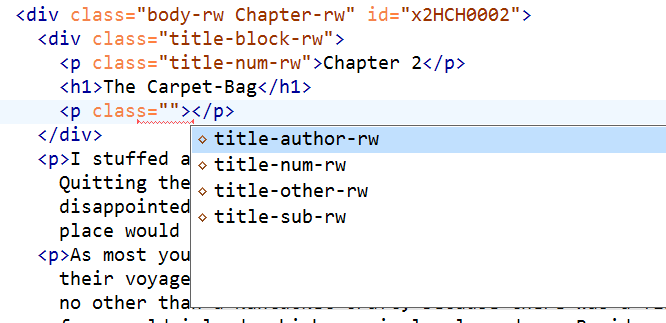
p.class choices
It should be noted that the epischema still doesn’t implement the FX spec faithfully in each regard. For example, after these screenshots have been taken, the author of this article discovered that FX permits several general-purpose layout attributes on every paragraph. So these have been included in the epischema, too.
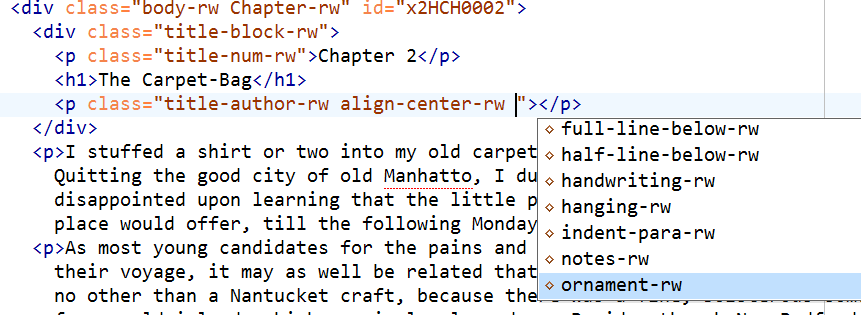
Additional layout classes.

No arbitrary classes that end in -rw allowed.

Other (non-rw) classes are allowed.
When attaching additional classes, one could wish that, for example, align-center-rw, align-left-rw, and align-right-rw be mutually exclusive. This is not stipulated by the FX spec, but it makes sense and it can be implemented in a Relax NG schema, but only at a hefty price: The slots for alignment, line-below, indentation, etc. classes would become positional. Mandatory classes that determine the type of paragraph will come first anyway, but then all other classes will have to appear in order, too. This might be acceptable from an authoring standpoint, but unfortunately, oXygen does not consider the list order when generating the class value suggestion lists. But even if this were fixed in oXygen, the issue that the order of class attributes shouldn’t matter in HTML at all would re-emerge. There may be documents that are supposed to be valid but that aren’t valid due to a class token order that does not match the order specified in the epischema. Again, this drawback is due to the limitation that there is no interleave in lists
An alternative for allowing a more arbitrary order of decorator classes is to forgo the list pattern in favor of regular expressions for the token combinations. A drawback of this approach, however, is that XML editors won’t be able to derive completion lists from regular expressions.
It is probably acceptable to enforce exclusions among class attributes by additional Schematron rules. Then the completion list might offer choices that will be rejected after a class value has been added. But at least it will offer a list of choices.
Prescriptive or permissive?
Another detail where the epischema is more restrictive than the underlying FX spec: It is selective with respect to the permitted location of div.block-rw.epigraph-rw. The first encounter with such an epigraph in the Moby Dick HTML file was within a div.title-block-rw. The
fx-title-block model was coined according to this structure, and div.block-rw.epigraph-rw was not permitted anywhere else.
It turned out that the next occurrence was outside of a title block, and it was flagged as invalid:

If an epischema is primarily used as a means to configuring content completion, tagging consistency might actually benefit from the epischema being a bit more opinionated than the Foundation XHTML spec.
Maybe the best approach will be a layered one:
- HTML as a base schema,
- permissive (spec-compliant) Foundation XHTML as an epischema,
- exclusions to work around Relax NG limitations as Schematron,
- prescriptive (authoring) Foundation XHTML as another epischema
and then stack them as needed into two different NVDL files, one for validation and lax editing, and the other one for strict editing.
A hierarchically nested schema for flat documents
One thing that Foundation XHTML does differently than conventional XML schemas is the (lack of) correspondence between element nesting and document hierarchy. In FX, all content chunks are inserted as children of div.galley-rw. While you have, for example, a nested
<front>
<div type="foreword">…</div>
</front>
<body>
<div type="part">
<div type="chapter">…</div>
…
<div type="chapter">…</div>
</div>
</body>
in TEI, FX requires you to create a flat sequence of classed chunk containers instead:
<div class="frontmatter-rw Foreword-rw">…</div>
<div class="body-rw part-rw">…</div>
<div class="body-rw Chapter-rw">…</div>
…
<div class="body-rw Chapter-rw">…</div>
It is interesting to note, though, that the Relax NG schema for these flat chunks looks nested indeed:
fx-Part =
element div {
fx-non-class-atts,
attribute class { list { "body-rw", "Part-rw", fx-other-class* } },
fx-title-block?,
fx-anything*
},
fx-specials*,
fx-Chapter+
This nested nature of the Relax NG patterns might reconcile orthodox publishing XML proponents a bit with FX’s flat composition approach.
A practical advantage of this schema in terms of editing guidance is that you cannot mix these chunks arbitrarily. Once you started with chapters, only more chapters may follow, no parts. Once you started with a part, the schema wraps this part and subsequent chapters into a virtual part element.
There are currently three possible “top-level”
hierarchy elements permitted by the epischema in the body: div.Unit-rw, div.Part-rw, or div.Chapter-rw.
fx-bodymatter =
(fx-Chapter+ | fx-Part+ | fx-Unit+)
Units have the same structure as parts, they consist of chapters. They are offered because some publishers (in particular, textbook publishers) call their highest-level divisions “units” rather than “parts”. The epischema enforces that parts and units do not intermingle, which is an authoring aid that comes for free* with this approach.
* not considering the licensing costs for XML editors that support epischemas for completion
Extending the epischema to journal articles
The basic epischema was created for a book, Moby Dick.
This is the complete schema that extends it for articles:
fx-Article =
element div {
fx-non-class-atts,
attribute class {
list { "body-rw", "Article-rw", fx-other-class* }
},
fx-title-block?,
fx-anything*
},
fx-specials*,
fx-Section*
fx-Section =
element div {
fx-non-class-atts,
attribute class {
list { "body-rw", "Section-rw", fx-other-class* }
},
fx-title-block?,
fx-anything*
},
fx-specials*
include "fx-html.rnc"
fx-bodymatter |= fx-Article
That is, it adds a choice to the body matter that allows you to
insert a single div.Article-nw
instead of div.Part-nw, div.Unit-nw, or div.Chapter-nw. This single article
start chunk may then be followed by multiple div.Section-nw chunks (and the
backmatter chunks).
Namespace or no namespace?
The whole epischema has been so far declared in a namespace-agnostic way. To make it work with namespaced content, it may be turned into a namespaced schema in two lines of code:
default namespace = "http://www.w3.org/1999/xhtml"
include "fx-html.rnc"
Of course there need to be different NVDL schemas for namespaced and
non-namespaced operation. The namespaced NVDL is given above, the non-namespaced variant can be obtained by simply replacing
<namespace ns="http://www.w3.org/1999/xhtml"> with
<namespace ns=""> and referring to a namespace-less
HTML5 schema. While a namespaced schema can be included by its
public URL, a namespace-less version has only been prepared by
the oXygen staff and is delivered with oXygen (see README.txt for configuration instructions). It should be noted
that it is sound advice to use an oXygen .xpr file to specify a catalog in any case in order to use local schemas that will
speed up validation and reduce network traffic.
JATS-style mixed citations
Foundation XHTML provides classes for citation tagging. The class
names correspond to elements that are used for
mixed-citation markup in the Journal Article Tag Suite.
The epischema provides context-dependent models that mimic the
grammar for mixed-citations. These models will be applied
in p.cite-rw paragraphs that are
permitted in div.backmatter-rw.References-rw chunks.
Such a citation doesn’t look nice as source code:
<div class="backmatter-rw References-rw">
<div class="title-block-rw">
<h1>Bibliography</h1>
</div>
<p class="cite-rw publication-type-journal-rw"><span
class="string-name-rw"><span class="surname-rw"
>Woodford-Williams</span>
<span class="given-names-rw">E</span></span>, <span
class="string-name-rw"><span class="surname-rw">McKeon</span>
<span class="given-names-rw">JA</span></span>, <span
class="string-name-rw"><span class="surname-rw">Trotter</span>
<span class="given-names-rw">IS</span></span>, <span
class="string-name-rw"><span class="surname-rw">Watson</span>
<span class="given-names-rw">D</span></span>, and <span
class="string-name-rw"><span class="surname-rw">Bushby</span>
<span class="given-names-rw">C</span></span>. <span
class="article-title-rw">The day hospital in the community care of
the elderly</span>. <span class="source-rw">Gerontology
Clinic</span>
<span class="year-rw">1962</span>; <span class="volume-rw">4</span>:
<span class="fpage-rw">241</span>–<span class="lpage-rw"
>256</span>.</p>
<p class="cite-rw publication-type-book-rw"></p>
</div>
However, content completion is also available in author mode, and this seems acceptable as an editing environment:
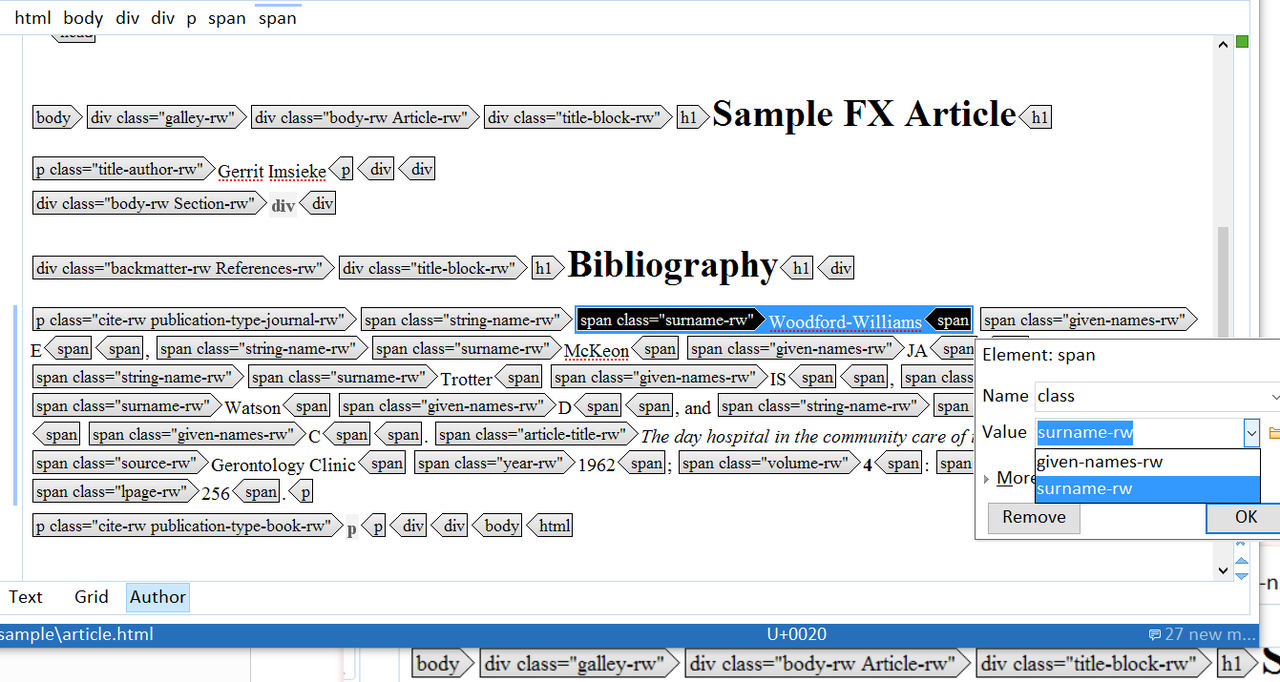
Bibliography entry in oXygen’s author mode (with visible tags&attributes switched on)
Note that the rules for JATS mixed-citations use up more than half of the epischema’s approx. (as of this writing) 1100 lines of code.
What about XSD 1.1?
Maybe it will work, thanks to xs:any/@notQName that enable the almost-anything pattern. We have some doubts though about XSD determinism requirements and schema association mechanisms (can it be used from NVDL?).
Can’t we merge a base schema and an epischema into a single RNG?
Relax NG is supposed to be “closed under union”, right?
This refers to being able to create a combined schema where each document that validates against the individual schemas also validates against the combined schema.
It doesn’t apply to our validation problem though. Just ask yourself which pattern you’d refer to in the start pattern. There is no way to specify that a given context (the top-level element in particular) should validate against two patterns simultaneously.
Conclusion
Epischemas are a useful, standards-based complement to other established validation and configuration approaches. The epischema that adds a prescriptive grammar for TEI div types has been used successfully in actual book production workflows since 2014. Given HTML’s permissive nature, HTML-first publishing workflows, not only the Foundation XHTML flavor, might be the area where epischemas really shine.