XProc 3.0 - Strategies for merging documents
November 16, 2020
Table of Contents
Introduction
XProc is an XML based programming language for processing documents in pipelines: chaining conversions and other steps together to achieve the desired results. As an introduction to XProc, the xml.com site contains an introductory article and an article about connecting ports. You can also visit the XProc 3.0 site itself for more information. And there's even a whole book dedicated to the language!
This article explores an often occurring problem when handling XML documents: merging several documents into one, using an XSLT stylesheet to bring data together. It's a bit more advanced than the other two and assumes you already know some XProc 3.0 (and a little XSLT) to start with.
The example code is freely available to play with. To run the examples you'll need an XProc processor. An overview of the available processors can be found here.
The example case
To illustrate the different merging strategies, I created an example that contains both data and several working pipelines. You can find it on GitHub: https://github.com/xatapult/xproc-merging-example.
We're going to merge three different XML documents. The merging itself is done by an XSLT stylesheet, which raises the question: how do we make all these documents available to the XSLT processor in an XProc 3.0 pipeline?
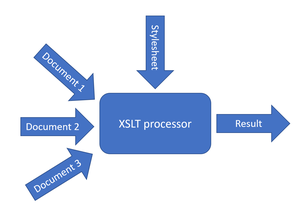
Now if it would be just like depicted in Figure 1, life would be rather easy. You designate one of the documents as your main input to the stylesheet and pull in the other two using the XPath doc() function.
But what if the documents are not directly available on disk? For instance because you have to create, transform or validate them first? Assume for instance that the source for one of the inputs is in Markdown and you need it in XML or HTML. Or you want to do XInclude processing up-front because the document contains references? Pre-processing documents before use is not uncommon, so let's see how we can do this using XProc 3.0, solving a simple, somewhat artificial, but nonetheless illustrating, problem.
The three documents we want to merge are:
An HTML template, straightforward, no pre-processing required:
Example 1.data/template.xml: Some HTML page template<html> <head> <title>Temperatures</title> </head> <body/> </html>
Our process is going to fill the
bodytag.A file with temperatures, linked to a city. An entry for a single city looks like this:
Example 2.data/temps/12345.xml: Temperature entry for a single city<citytemp id="12345" temp="20"/>All these entries come from different sources, stored in a document of its own. They're combined in a master file that XIncludes everything:
Example 3.data/temps.xml: Temperature entries combined, using XInclude<citytemps date="2020-10-10" xmlns:xi="http://www.w3.org/2001/XInclude"> <xi:include href="temps/12345.xml"/> <xi:include href="temps/56789.xml"/> </citytemps>
A document that links city identifiers to names:
Example 4.data/city-ids.xml: Temperature entry for a single city<city-ids> <city-id id="12345" name="Amsterdam"/> <city-id id="56789" name="Moscow"/> </city-ids>
Now assume for this use case we don't really trust the production of this document. Therefore we want to make sure it's valid before we process it. The schema for this is in
data/xsd/city-ids.xsd.
All together, the full flow we want to implement is:
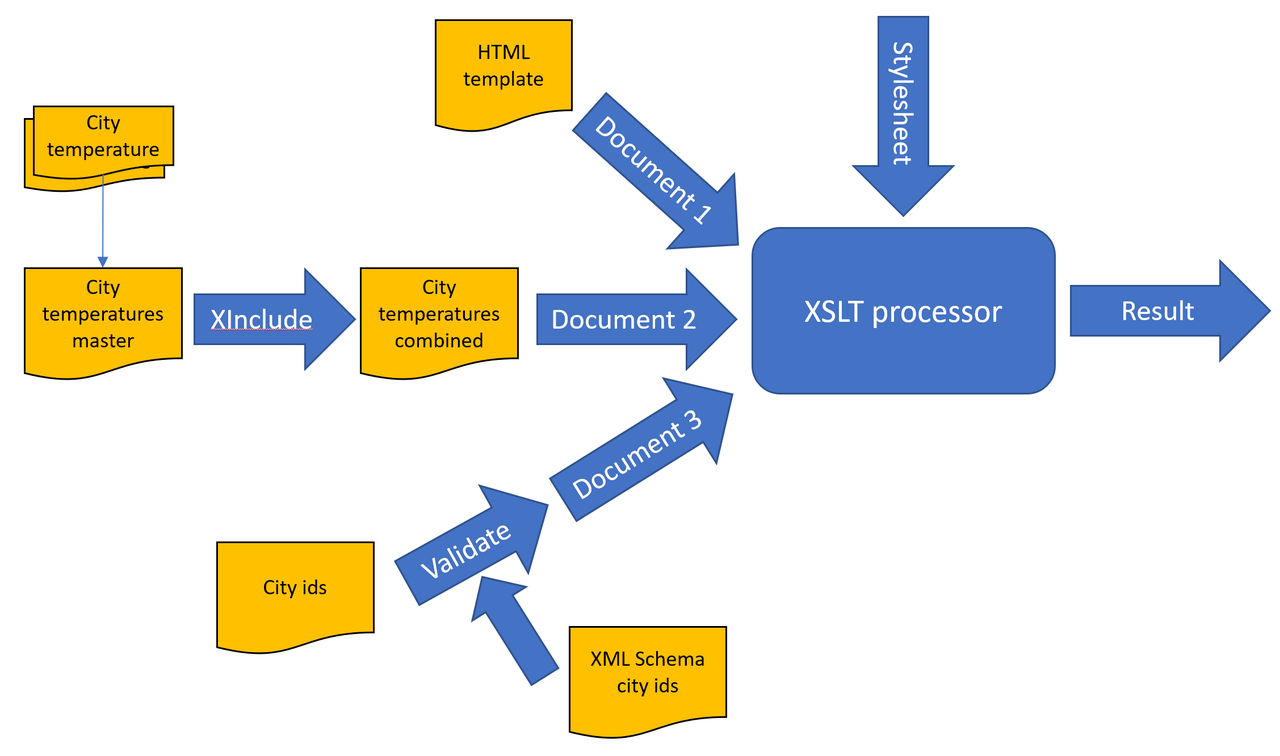
The result will be a boring HTML page, listing cities and temperatures. For didactic purposes, this is kept deliberately simple. However, let nothing stand in your imagination's way to invent (and implement) more complicated scenarios…
Using disk as temporary storage (not recommended!)
If you're new to XProc and/or have implemented pipeline-like processing using Ant or command/shell scripts, you might be tempted to write intermediate results to disk. Yes, you can definitely do that in XProc but it's definitely not recommended. Why would you serialize a document to disk and, after that, re-parse it into memory, if you already have it in memory? That's an utter gross waste of CPU cycles. And it also needs a rather complicated pipeline. Nonetheless, let's implement it this way to see how it can be done, just for the fun of it.
I actually encountered a situation where I needed this: A third-party stylesheet I had to use (and couldn’t change) expected some of its input documents on disk. So I had no other choice than to write all inputs, which were computed elsewhere in my XProc pipeline, to disk first.
Here is an XProc 3.0 pipeline that writes the combined temperatures document to a temporary file. It uses the template file as main input for the merging stylesheet and passes the names of the other input files as parameters:
implementation-1/implementation-1.xpl: Pipeline that uses temporary files for intermediate results<p:declare-step version="3.0" name="main-pipeline"
xmlns:p="http://www.w3.org/ns/xproc"
xmlns:xs="http://www.w3.org/2001/XMLSchema">
<!-- 1 - Declare the input ports: -->
<p:input port="template" primary="false" sequence="false"
content-types="xml" href="../data/template.xml"/>
<p:input port="temps" primary="false" sequence="false"
content-types="xml" href="../data/temps.xml"/>
<p:input port="city-ids" primary="false" sequence="false"
content-types="xml" href="../data/city-ids.xml"/>
<!-- 2 - Declare the output port: -->
<p:output port="result" primary="true" sequence="false"
content-types="xml"
serialization="map{'method': 'html', 'indent': true()}"/>
<!-- ======================================================================= -->
<!-- 3 - Create a temporary file and catch its name: -->
<p:file-create-tempfile delete-on-exit="true" suffix=".xml"/>
<p:variable name="temps-filename" as="xs:string" select="string(.)"/>
<!-- 4 - Compute the full temperature document, write it the temporary file: -->
<p:xinclude>
<p:with-input pipe="temps@main-pipeline"/>
</p:xinclude>
<p:store href="{$temps-filename}" name="write-temps-to-disk"/>
<!-- 5 - Validate the city-ids document. If this is invalid the pipeline will fail: -->
<p:validate-with-xml-schema name="validate-city-ids-document">
<p:with-input pipe="city-ids@main-pipeline"/>
<p:with-input port="schema" href="../data/xsd/city-ids.xsd"/>
</p:validate-with-xml-schema>
<!-- 6 - Catch the name of the city-ids document: -->
<p:variable name="city-ids-filename" as="xs:string" select="base-uri(.)"
pipe="city-ids@main-pipeline"/>
<!-- 7 - Do the XSLT processing: -->
<p:xslt
parameters="map{
'temps-filename': $temps-filename,
'city-ids-filename': $city-ids-filename
}"
depends="write-temps-to-disk validate-city-ids-document">
<p:with-input pipe="template@main-pipeline"/>
<p:with-input port="stylesheet" href="implementation-1.xsl"/>
</p:xslt>
</p:declare-step>
The three necessary documents are passed in through input ports:
Since it's not clear which input is primary, I choose to declare them all as non-primary. But there's nothing wrong with favouring one of them over the others and make it primary (
primary="true").With more than one input port,
primary="false"is the default, so you could have omitted theprimaryattribute.I was deliberately verbose in declaring the ports, specifying everything I could:
sequence="false" content-types="xml". This is not strictly necessary but it will make your pipeline more robust: if you ever accidentally pass in multiple documents or a non-XML document, the step will fail. I consider it good practice.sequence="false"is the default, so you could have omitted thesequenceattribute.To simplify running the pipeline, default document connections were added to the ports, using the
hrefattribute. If you specify some other connection for one of these input ports (on the command line for instance), this default will be ignored.
The output port is declared as one that, from inside the pipeline, receives XML (
content-types="xml"), but advises the processor to use HTML when it serializes the document (writes it to disk) (serialization="map{'method': 'html', …}"). Fortunately for us, the processor usually follows advice…The
p:file-create-tempfilestep creates a temporary file and outputs the absolute URI of this in a singlec:resultelement. Thedelete-on-exit="true"attribute tells the processor to try to conveniently delete the temporary file after all processing is finished.After the temporary file is created, we put its URI in the
temps-filenamevariable.The
p:xincludestep resolves the XIncludes in the temperatures file. After that, we write it to the temporary file we created previously.Then we validate the city identifiers document. If this fails, an error will be thrown and we're done.
Since we want our stylesheet to read all additional documents from disk, we need the URI of the city identifiers document. Here we store it in the
city-ids-filenamevariable.Having doubts about this construction? You should! This will fail miserably if we're ever going to use this pipeline as a step in another pipeline. In that case there's no guarantee that the city identifiers document, coming in through the
city-idsport, is on disk at all. Maybe it was created or computed… For this simple case it works, but don't rely on these kinds of constructions in more complex projects.Finally we transform it using XSLT. The main input to this transformation is our HTML template document, coming in through the
templateport. We pass the filenames for the other two documents using thep:xlststep'sparametersoption.
It depends...
A stylesheet that creates the final result looks like this (not intended as a particularly illustrative
example of an XSLT stylesheet, just short. xsl:for-each haters, please hold your fire ;) ):
implementation-1/implementation-1.xsl: Stylesheet for Example 5
<xsl:stylesheet version="3.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
exclude-result-prefixes="#all" expand-text="true">
<xsl:mode on-no-match="shallow-copy"/>
<xsl:param name="temps-filename" as="xs:string" required="yes"/>
<xsl:param name="city-ids-filename" as="xs:string" required="yes"/>
<xsl:template match="body">
<xsl:copy>
<xsl:apply-templates select="@*"/>
<xsl:for-each select="doc($temps-filename)/*/citytemp">
<xsl:variable name="city-id" as="xs:string" select="@id"/>
<p>{doc($city-ids-filename)/*/city-id[@id eq $city-id]/@name}: {@temp}</p>
</xsl:for-each>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>
Wrapping all documents into one
Using a temporary file to store a constructed intermediate XML document, as we did in the section called “Using disk as temporary storage (not recommended!)”, is not only a waste of computing resources, it also results in an unnecessarily complicated pipeline (Example 5). So how can we do better? A much simpler and pretty common strategy is to take all documents, wrap them up in an encompassing document and feed this to the XSLT stylesheet.
The wrapped document we're going to create will look like this:
<wrapper-root-element>
<html>
…
</html>
<citytemps>
…
</citytemps>
<city-ids>
…
</city-ids>
</wrapper-root-element>
And here is a pipeline that creates and uses such a wrapped document:
implementation-2/implementation-2.xpl: Pipeline that wraps all documents into one as input for the XSLT
transformation<p:declare-step version="3.0" name="main-pipeline"
xmlns:p="http://www.w3.org/ns/xproc"
xmlns:xs="http://www.w3.org/2001/XMLSchema">
<p:input port="template" primary="false" sequence="false"
content-types="xml" href="../data/template.xml"/>
<p:input port="temps" primary="false" sequence="false"
content-types="xml" href="../data/temps.xml"/>
<p:input port="city-ids" primary="false" sequence="false"
content-types="xml" href="../data/city-ids.xml"/>
<p:output port="result" primary="true" sequence="false"
content-types="xml"
serialization="map{'method': 'html', 'indent': true()}"/>
<!-- ======================================================================= -->
<!-- 1 - Validate the city-ids document. If this is invalid the pipeline will fail: -->
<p:validate-with-xml-schema name="validate-city-ids-document">
<p:with-input pipe="city-ids@main-pipeline"/>
<p:with-input port="schema" href="../data/xsd/city-ids.xsd"/>
</p:validate-with-xml-schema>
<!-- 2 - Compute the full temperature document -->
<p:xinclude name="temps-file-xincluded">
<p:with-input pipe="temps@main-pipeline"/>
</p:xinclude>
<!-- 3 - Create a sequence of all necessary documents and wrap them in a root element: -->
<p:wrap-sequence wrapper="wrapper-root-element">
<p:with-input
pipe="
template@main-pipeline
result@temps-file-xincluded
result@validate-city-ids-document
"/>
</p:wrap-sequence>
<!-- 4 - Do the XSLT processing: -->
<p:xslt>
<p:with-input port="stylesheet" href="implementation-2.xsl"/>
</p:xslt>
</p:declare-step>
(For an explanation of the input and output port declarations in the prolog, see the explanation of Example 5.)
We validate the city identifiers document. If this fails, an error is thrown and we're done.
When nothing’s wrong, the
p:validatestep acts like ap:identitystep and outputs its input, unchanged (that is to say, it might add the Post-Schema-Validation-Infoset (PSVI) annotations but that’s something we’re not using here).The
p:xincludestep resolves the XIncludes in the temperatures file.We create the wrapped document by feeding the
p:wrap-sequencestep a sequence of the three documents, using three whitespace separated entries in thep:with-input'spipeattribute. Each entry is a connection to a port:The template document is inserted directly from the main pipeline’s
templateport.The temperatures document is inserted from the output (
resultport) of thep:xincludestep.The city identifiers document is inserted from the output (
resultport) of thep:validatestep.Notice that we explicitly read it from the output of
p:validate, not from the main pipeline’scity-idsport, even though both documents have the same contents. Doing it like this creates an explicit dependency and ensures thatp:validateis run beforep:xslt.
Now XSLT can do its magic on the wrapped documents. It feeds automatically into the
p:xslt's primarysourceport because of the implicit connection between thep:wrap-sequenceandp:xsltsteps.
Here's a simple XSLT stylesheet that uses these wrapped documents:
implementation-2/implementation-2.xsl: Stylesheet for Example 8
<xsl:stylesheet version="3.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
exclude-result-prefixes="#all" expand-text="true">
<xsl:mode on-no-match="shallow-copy"/>
<xsl:template match="/">
<xsl:apply-templates select="/*/html"/>
</xsl:template>
<xsl:template match="body">
<xsl:copy>
<xsl:apply-templates select="@*"/>
<xsl:for-each select="/*/citytemps/citytemp">
<xsl:variable name="city-id" as="xs:string" select="@id"/>
<p>{/*/city-ids/city-id[@id eq $city-id]/@name}: {@temp}</p>
</xsl:for-each>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>
Passing documents as parameters
Yet another way to do the same is by passing the additional documents to the XSLT stylesheet as document parameters.
That is, as parameters of type document-node(). You might, like I was, be surprised that a thing like this is even possible:
limiting parameters in stylesheets to strings was always the safe and easy way. But with the arrival of XPath 3.1 you can now also use
other data types for this.
A pipeline that exploits this feature looks like this:
implementation-3/implementation-3.xpl: Pipeline that uses document parameters to pass additional documents to the XSLT
transformation<p:declare-step version="3.0" name="main-pipeline"
xmlns:p="http://www.w3.org/ns/xproc"
xmlns:xs="http://www.w3.org/2001/XMLSchema">
<p:input port="template" primary="false" sequence="false"
content-types="xml" href="../data/template.xml"/>
<p:input port="temps" primary="false" sequence="false"
content-types="xml" href="../data/temps.xml"/>
<p:input port="city-ids" primary="false" sequence="false"
content-types="xml" href="../data/city-ids.xml"/>
<p:output port="result" primary="true" sequence="false"
content-types="xml"
serialization="map{'method': 'html', 'indent': true()}"/>
<!-- ======================================================================= -->
<!-- 1 - Validate the city-ids document. If this is invalid the pipeline will fail: -->
<p:validate-with-xml-schema name="validate-city-ids-document">
<p:with-input pipe="city-ids@main-pipeline"/>
<p:with-input port="schema" href="../data/xsd/city-ids.xsd"/>
</p:validate-with-xml-schema>
<!-- 2 - Compute the full temperature document -->
<p:xinclude name="temps-file-xincluded">
<p:with-input pipe="temps@main-pipeline"/>
</p:xinclude>
<!-- 3 - Refer to the documents using document-node() type variables: -->
<p:variable name="city-temps-document" as="document-node()" select="."/>
<p:variable name="city-ids-document" as="document-node()" select="."
pipe="result@validate-city-ids-document"/>
<!-- 4 - Do the XSLT processing: -->
<p:xslt parameters="map{
'city-temps-document': $city-temps-document,
'city-ids-document' : $city-ids-document
}">
<p:with-input pipe="template@main-pipeline"/>
<p:with-input port="stylesheet" href="implementation-3.xsl"/>
</p:xslt>
</p:declare-step>
(For an explanation of the input and output port declarations in the prolog, see the explanation of Example 5.)
Like in Example 8, validate the city identifiers document.
The
p:xincludestep resolves the XIncludes in the temperatures file.To be able to pass the additional documents, we create two variables of type
document-node():The first one,
city-temps-document, refers, by implicit connection, to the document that comes out of the precedingp:xincludestep.The second one,
city-ids-document, refers, by explicit connection usingpipe="result@validate-city-ids-document", to the document that comes out of thep:validatestep. Again, like in the section called “Wrapping all documents into one”, we use this and not thecity-ids@main-pipelineport to make sure thep:validateruns before thep:xslt.
The
p:xsltstep runs with the template document fed explicitly into its primary port (by<p:with-input pipe="template@main-pipeline"/>). The additional documents are passed in as parameters using the map in theparametersoption.
And a simple XSLT stylesheet that uses these parameters:
implementation-3/implementation-3.xsl: Stylesheet for Example 10
<xsl:stylesheet version="3.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
exclude-result-prefixes="#all" expand-text="true">
<xsl:mode on-no-match="shallow-copy"/>
<xsl:param name="city-temps-document" as="document-node()" required="yes"/>
<xsl:param name="city-ids-document" as="document-node()" required="yes"/>
<xsl:template match="body">
<xsl:copy>
<xsl:apply-templates select="@*"/>
<xsl:for-each select="$city-temps-document/citytemps/citytemp">
<xsl:variable name="city-id" as="xs:string" select="@id"/>
<p>{$city-ids-document/city-ids/city-id[@id eq $city-id]/@name}: {@temp}</p>
</xsl:for-each>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>
Passing all documents as a collection
One more way to do the same is by passing all the documents as a collection. This requires some explanation upfront:
We’re going to tell
p:xsltthat it should start by invoking a named template (instead of apply templates) by setting thetemplate-nameoption (to the name of the template we want to invoke).Setting the
template-nameoption has the intended additional effect of making all documents on thesourceport available as the default collection, accessible with the XPathcollection()function.We then pass all our documents (the HTML template, the city temperatures and the city identifiers) as a sequence (of documents) on
p:xlst'ssourceport.With all this, in the XSLT stylesheet, the
collection()function now returns the sequence of our three input documents (count(collection())will be3). The root element of, for instance, the city temperatures document can be accessed bycollection()/city-temperatures.
A pipeline that uses this collection feature looks like this:
implementation-4/implementation-4.xpl: Pipeline that uses a collection to pass documents to the XSLT transformation<p:declare-step version="3.0" name="main-pipeline"
xmlns:p="http://www.w3.org/ns/xproc"
xmlns:xs="http://www.w3.org/2001/XMLSchema">
<p:input port="template" primary="false" sequence="false"
content-types="xml" href="../data/template.xml"/>
<p:input port="temps" primary="false" sequence="false"
content-types="xml" href="../data/temps.xml"/>
<p:input port="city-ids" primary="false" sequence="false"
content-types="xml" href="../data/city-ids.xml"/>
<p:output port="result" primary="true" sequence="false"
content-types="xml"
serialization="map{'method': 'html', 'indent': true()}"/>
<!-- ======================================================================= -->
<!-- 1 - Validate the city-ids document. If this is invalid the pipeline will fail: -->
<p:validate-with-xml-schema name="validate-city-ids-document">
<p:with-input pipe="city-ids@main-pipeline"/>
<p:with-input port="schema" href="../data/xsd/city-ids.xsd"/>
</p:validate-with-xml-schema>
<!-- 2 - Compute the full temperature document -->
<p:xinclude name="temps-file-xincluded">
<p:with-input pipe="temps@main-pipeline"/>
</p:xinclude>
<!-- 3 - Do the XSLT processing: -->
<p:xslt template-name="process-documents">
<p:with-input
pipe="
template@main-pipeline
result@temps-file-xincluded
result@validate-city-ids-document
"/>
<p:with-input port="stylesheet" href="implementation-4.xsl"/>
</p:xslt>
</p:declare-step>
(For an explanation of the input and output port declarations in the prolog, see the explanation of Example 5.)
Like in Example 8, validate the city identifiers document.
The
p:xincludestep resolves the XIncludes in the temperatures file.Invoke the XSLT stylesheet with the
template-nameoption set toprocess-documents. This will have the XSLT processor look for a named template calledprocess-documentsand start there.We feed the primary
resultport a sequence of our three documents, using three whitespace separated entries in thep:with-input'spipeattribute. Each entry is a connection to a port. This is similar to what we did in Example 8 for the input top:wrap-sequence.
And the XSLT stylesheet that uses the collection looks like this. Notice the
process-documents named template. This is where the processing will start.
implementation-4/implementation-4.xsl: Stylesheet for Example 12<xsl:stylesheet version="3.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
exclude-result-prefixes="#all" expand-text="true">
<xsl:mode on-no-match="shallow-copy"/>
<xsl:template name="process-documents">
<xsl:apply-templates select="collection()/html"/>
</xsl:template>
<xsl:template match="body">
<xsl:copy>
<xsl:apply-templates select="@*"/>
<xsl:for-each select="collection()/citytemps/citytemp">
<xsl:variable name="city-id" as="xs:string" select="@id"/>
<p>{collection()/city-ids/city-id[@id eq $city-id]/@name}: {@temp}</p>
</xsl:for-each>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>
Wrap up
As we've seen, there are several ways to pass documents to an XSLT stylesheet for merging:
By using the file system as intermediate storage (the section called “Using disk as temporary storage (not recommended!)”). Definitely not recommended.
By wrapping the documents in some container document and pass this to the stylesheet (the section called “Wrapping all documents into one”).
By passing the additional documents to the stylesheet as document type parameters (the section called “Passing documents as parameters”).
By passing the documents as a collection (the section called “Passing all documents as a collection”).
I don't really have a recommendation which one to use (except not to use the first). Wrapping documents (number 2) is for me personally the "classic" way to do this, leading back to my extensive XProc 1.0 pipelines. It has the slight advantage that the input to your XSLT stylesheet is easy to emulate (just create an appropriate XML document), allowing you to develop and test the stylesheet without having to run it in an XProc context. But the other approaches also have their merits. You can even mix the approaches if that suits your requirements. And maybe there are more ways to do this (if you find one, let me know).
So: experiment, pick, and choose. Happy XProc-ing!