What is XSL-FO?
January 1, 2017
Table of Contents
The Extensible Stylesheet Language Formatting Objects (XSL-FO) specification is to the world of paginated content what the HTML specification is to the world of the browser display. XSL-FO is used to express the semantics of the bounded form of print and paper with fixed dimensions, whereas HTML is used to express the semantics of the unbounded form of a browser window with elastic width and arbitrary length. Not totally foreign to each other, both specifications share a common use of Cascading Stylesheets (CSS) properties for basic appearance.
We often take the printed form of information for granted, yet how many of us are satisfied with the print functionality from a web browser? How many times have you printed a lengthy web document and found the paginated result to be as easily navigated as the electronic original? The paper world has not disappeared, but printing from a web browser fails to equip the reader to access your lengthy content easily.
There are times when we need to distribute our information on paper, or at least paginated with the appearance of paper to give our users the option of using paper should they wish. We may have regulatory constraints imposed on us to produce the paper form, if not the paper itself, for legacy reasons. A 40,000 page aircraft maintenance manual submitted to federal authorities to satisfy legal obligations may still have to be produced even though the content may be more useful to the worker on the line as an interactive electronic application. You have your content in XML with which to publish it for different audiences in different forms and formats. You may need one or more of those formats to be paper, or at least to be paginated into PDF with the electronic appearance of physical paper.
The W3C published the Extensible Stylesheet Language (XSL) with its formatting objects used to express how to compose and paginate information for this purpose. Unfortunately, stylesheet writers find this important specification a bit opaque, because it isn't written for them, it is written for the XSL-FO processor implementer. But the basic concepts are straightforward to understand and traditional typesetting terminology is used appropriately to equip the stylesheet writer to get the desired results. Supported by multiple vendors, most offering features that extend beyond the W3C specification, when you need to create a print rendition of your content, it is the right approach to use.
1. The task at hand
The essence of the need for a vocabulary of print semantics is that the navigation tools available to the paper user accessing your content are different than such tools available to the browser user accessing your content. Whereas a hyperlink in a browser or in a PDF file quickly moves the user to a target location in the content, that traversable underscored blue hyperlink in and of itself doesn't equip the user of physical paper to take them to the target page.
Of course hyperlinks do exist in paper, often in the form of phrases such as "(see page 37)" and in tables of content, but they only work if the paper collection has an unambiguous and reliable labeling of page numbers on each page so that the user can find the target page. We've used page numbers since we've used books, but have we realized that page numbers are navigation tools? Such a tool has a resolution of the number of pages of paper. The ambiguity point is important. Often one uses a different presentation, such as lower case Roman numerals in front matter, to distinguish the same page number showing up twice in a collection of pages.
Another navigation tool is the use of running heads. It is common to see on facing pages a book's title on one side's header and the chapter's title on the other side's header. Also common is to have the running subsection information in both headers, indicating the section information that starts first on the one page and the section information that starts last on the other page. The very same application of the section header tool is the use of dictionary heads, reporting the first word on the one page and the last word on the other page.
Yet another navigation tool not used as much recently as before is the "thumb guide". The cheap thumb guide involves simply bleeding ink over the cut line of the paper. Groups of pages all contribute to the visibility of the section on the edge of the book when the book is closed. An index page showing each of the thumbs can guide the user to quickly find where in the book any given section is found. The expensive thumb guide involves a cutting process after publication that makes the first page of a section visible with identifying information one can see while the book remains closed. Many printed dictionaries had this navigation feature in the past.
Without the bounded folios of pages, these navigation tools have no role in a browser page of arbitrary length. No such semantics are available in HTML and CSS 2. While in 2015, the Paged Media Module of CSS 3 introduced a simple page model to CSS, the finessing supported in XSL-FO has successfully been deployed in production environments worldwide since 2001. Arguments regarding fidelity preservation between screen and print renderings have long been addressed using XSL-FO as described later.
Moreso than ever, the importance of dealing with internationalized text in our publications is growing. We need our publication tools to deal with mixed bi-directional text and appropriate margins and bindings for all writing modes. XSL-FO inherits this important functionality from standards used with SGML to properly compose and paginate documents around the world.
2. Where to use XSL-FO
XSL-FO has been successfully deployed in a wide range of high-volume real-world applications. The high volume can be the measurement of over a thousand pages for a single catalogue with three columns listing US charitable foundations, or tens of thousands of pages for a single aircraft maintenance manual. The high volume can be the measurement of a single run of five million customized one-page subscriber letters for patients of a Californian HMO, thousands of German train tickets printed in real time at a kiosk, thousands of US intelligence documents printed differently for different Commands and Bases, and hundreds of both short and long parliamentary bills and acts printed for the New Zealand Government.
It is important to note, however, that XSO-FO is appropriate for content-based publishing but not appropriate for layout-based publishing. This is exemplified by contrasting the requirements for publishing an aircraft maintenance manual and those for publishing an article in a magazine. It is the content of the maintenance manual or of the legislation that is of prime importance, and the page composition considerations respond to the content. No content can possibly be sacrificed. But it is the overall layout of a magazine article that is the governing factor in page composition for a magazine. If there is too much content for the area and its shape put aside for it on the magazine's page, and visual compression tricks are insufficient to the task, the content is edited in order to fit the available layout constraints. If there is too little content and visual expansion tricks don't help, maybe it is time for another photograph to be included.
I do not consider journal articles to be the same as magazine articles. Journal articles are another example of sacrosanct content driving the publishing process, thus being very suitable for automated page composition. Whereas magazine articles are an example of one-off publishing that isn't suitable for automation. There are plenty of desktop publishing tools and even XML-based composition tools for one-off publishing that would not be appropriate for high-volume publishing. Creating a separate unique XSL-FO stylesheet for each XML document because of custom layout requirements defeats the leverage offered by XSL-FO to compose tens or hundreds or thousands of pages from either a single large XML document or many similarly-structured XML documents.
There is, however, a mostly historical high-volume publishing requirement for which XSL-FO cannot be used. Loose-leaf publishing was a very common approach to maintaining large publications, such as aircraft maintenance manuals, effectively from a materials cost perspective. Not, necessarily, from a people cost. In loose-leaf publishing, after the initial publication of a document, modifications to the content are distributed using change pages. Users of the publication are responsible for removing the old version of the changed pages and replacing them with the new version of changed pages. When the number of new pages in a given change sequence exceeds the number of old pages, A-pages are injected in advance of the first unchanged page. For example, a four-sided change to page 38 of a double-sided publication would produce the three double-sided pages 37, 38, 38A, 38B, 38C and the intentionally-left-blank page 38D. These would be sent out to users and the publication would not be up-to-date until the user effected the change in the physical stack of paper.
XSL-FO is ill-suited for loose-leaf publishing because there are no page boundary memory semantics in the language. The XSL-FO user always specifies sequences of pages and never just a single page. The XSL-FO user is unaware when writing a stylesheet of where in the flow of the user's content page breaks are going to end up in the printed form. The XSL-FO processor manages the page composition process solely on the intents expressed by the stylesheet writer for the desired results, and on the contingencies expressed by the stylesheet writer for situations that trigger undesirable results.
Moreover, two conforming implementations of XSL-FO will likely produce different page images from a single XSL-FO file. The burden is on the stylesheet writer to override allowed vendor defaults for formatting properties to try and get two implementations to closely mimic each other, but the precision is never guaranteed. A large XML source may produce 700 pages when using one vendor's conforming implementation of XSL-FO, while the same source produces 704 pages when using another. A simple example triggering this difference is two hyphenation and justification algorithms will produce different line breaks, thus producing different line counts, thus producing different page counts.
The accuracy of automated production of the total result, without the burden and possible human error of maintaining change pages, offsets the historical use of change pages and the possible nuanced differences between vendor implementations. The higher cost of people time adds to the negatives of human error. Many companies are opting for always producing a complete publication.
Consider the nature of your publications when deciding whether or not to use XSL-FO. High-volume results will leverage your investment in the XSL-FO stylesheets. Producing very large publications or many small publications will be automated with contingencies for nuanced output. Internationalized content will be correctly presented to all users as required.
3. Fidelity in parallel print and browser renderings
Many users require their publications found in a single XML source to be published simultaneously in both PDF and HTML. It is a common design plan to create parallel XSLT transformations, one for a PDF result and one for an HTML result, double the effort to get the two results from the one source.
In many such projects there is an important fidelity requirement. Rather than exploit the browser screen for a drastically different presentation than the printed form, the requirement to make the HTML look almost identical to the PDF is paramount, as the printed form, historically, is the governing model to follow.
Two real-world examples of such projects are the publishing of New Zealand Legislation
bills and acts to both PDF and HTML, and the publishing of US Intelligence documents to both
PDF and HTML. The results of the legislation publishing are publicly visible. Consider the
HTML and PDF renderings of the NZ Health and Safety Act example found at http://www.legislation.govt.nz/act/public/2015/0070/latest/DLM5976660.html:
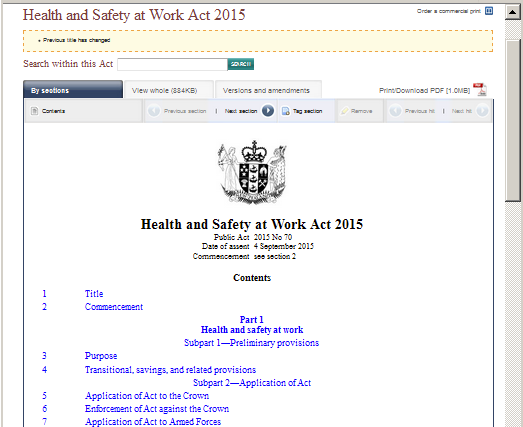
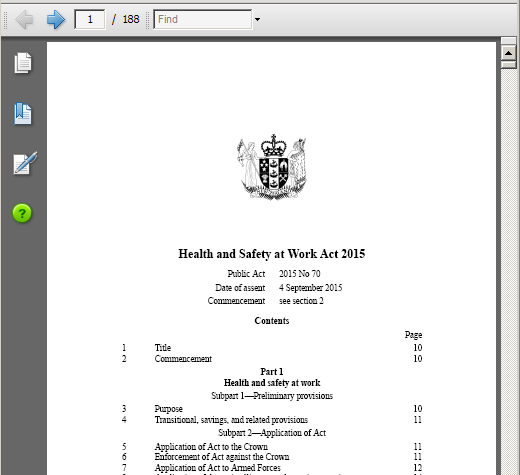
In both projects the fidelity of the two outputs for each XML input is guaranteed by using a particular data flow of transformation, while still accommodating the differences in navigation semantics. Note in the legislation examples how the HTML rendering of the table of contents is comprised of blue hyperlinks, while the PDF rendering of the table of contents includes page numbers. Not shown is that the page numbers and the section titles themselves are also hyperlinks in the PDF, but this would be revealed to the user hovering over the text using a PDF reader.
Creating two parallel XSLT transformations from a single source, one for the HTML result and one for the XSL-FO result, would be a typical but naïve approach to this problem. Change requests would affect each transformation separately. It would be a challenge to promise fidelity between the two resulting publications because of the burden of interpreting the semantics of the input XML the same way to produce the same results for both transformations.
In these two projects, and many others, such fidelity is guaranteed to the client by performing a single semantic interpretation and transformation of the source XML using a specific XSLT to create a master presentation expressed in XSL-FO. This is followed by a mechanical semantic-free transformation of the XSL-FO into HTML using a generic XSLT. This focuses all of the "smarts" of creating the presentation into a single transformation for maintenance purposes, and guarantees the results to be identically structured because it is the one result structure that is producing both PDF and HTML publications.
This approach is enabled readily by the tolerance of XSL-FO processors to ignore elements and attributes not in the XSL-FO vocabulary. Having elements and attributes not in the XSL-FO vocabulary is key to supporting custom vendor extensions offering publishing features that go beyond the W3C specification. Augmenting the XSL-FO with cues for HTML generation is masked from an XSL-FO processor because such augmentations look simply like unrecognized vendor extensions to be ignored. An XSL-FO processor is looking at the instance only to support the XSL-FO vocabulary and known extension vocabularies representing additional behaviours.
Consider this data flow diagram where the initial transformation interpreting the semantics of the source XML document creates XSL-FO, augmenting it with signals for HTML generation, and so depicted using the "XSL-FO++" label. This XSL-FO++ is forwarded to the vendor's standard XSL-FO processor to produce the paginated result as PDF or paper, and any augmentations are ignored.
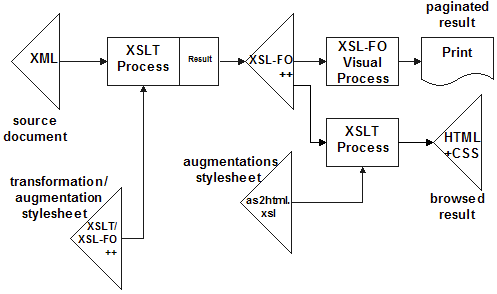
The XSL-FO++ instance is then transformed using the augmentations stylesheet. This transformation is free of any knowledge of the source XML semantics and free of the interpretation of XSL-FO appearance properties. Triggering on the HTML information in the augmentations annotating the XSL-FO elements, usually in conjunction with the XSL-FO element type, the XSLT creates the pure HTML and CSS needed to present the information found already interpreted in the XSL-FO textual content and graphic references. If there are nuances to be realized in the created HTML, the original XSLT transformation annotates the XSL-FO++ with additional augmentations needed for such decision making in the final step.
In the legislation project it was decided that the XSL-FO constructs created from XML semantic constructs would record the source semantic construct as a CSS class name with which to style the generated HTML element in its entirety. There are zero style or appearance properties found in the HTML result. This divorced tweaking the HTML appearance and nuanced CSS properties from the XSL-FO transformation. It allowed the browser team from a separate project contractor to focus on the raw HTML constructs and CSS class properties based on recognizing the semantic construct as the class name. That contractor had no involvement in the XSL-FO++, nor any responsibilities for interpreting the semantic source XML, other than coordinating the catalogue of classes to be expected to be referenced in the HTML. Fragmenting the resulting HTML into pieces, massaging the links as required, was also accomplished by the contractor producing the piecemeal web product.
More detail regarding the system implementation of the US Intelligence document publishing
project can be found at http://www.CraneSoftwrights.com/links/ipepaper.htm. There are
no examples of the outputs, but the publishing stylesheet design is described in some detail.
It differs slightly by the absence of an external CSS class stylesheet. In this project all
presentation properties were realized explicitly using XSL-FO properties translated to HTML
and internal CSS styles. No external CSS stylesheets nor classes were used.
The intelligence documents publishing project predates the legislation publishing project by 10 years. Divorcing the HTML/CSS styling from the XSL-FO styling in the legislation project has proven to be a more robust and maintainable approach than the earlier tightly-bound approach used in the intelligence documents project. It also enabled the client to use two contractors in parallel, the second one focused on merely the appearance and not the structuring of the result.
4. A historical note regarding the specification's name
It should be noted that the name "XSL-FO" is what the XML community has been calling the W3C specification named "XSL" for just "Extensible Stylesheet Language". The community needed to disambiguate the terminology for those confusing "XSL" with "XSLT", the Extensible Stylesheet Language Transformations.
Those who are confused cannot be faulted for this ambiguity. The process of formatting information involves two distinct steps: rearranging the information from the order that was authored into the order that is being presented, and then decorating the information that is being presented in a way suitable to be read. The very first drafts of the Extensible Stylesheet Language (XSL) addressed all of the formatting by combining both the transformation aspect found in chapter two and the page composition aspects found in all of the other chapters.
The act of transformation, or more accurately the creation of a new arrangement of information from an old arrangement, became a very useful technology in and of itself. This became the very successful standalone specification XSLT that has enjoyed a life of its own. Chapter two of the XSL specification still exists and still addresses the transformation aspect of formatting, it just is now a stub that points to the XSLT specification.
In diagrams and in text one should regard "XSL" and "XSL-FO" as synonymous references to the XML vocabulary of page composition semantics for content-based layout, and XSLT as the reference to the standalone transformation vocabulary.
5. Formatting vs. Rendering
Let us first take a step back. When creating or original XML we should be designing the
structures around our business processes responsible for expressing and maintaining the
information, instead of using structures aimed at presentation. Unless, of course, if what we
are describing is presentation oriented, but a lot of XML describes the semantic aspects of a
corpus of information. The semantic constructs wrap parseable character data
(#PCDATA) containing the written word and other textual values. For a
maintenance manual, this would include constructs such as <caution>,
<warning>, <procedure> and
<step>.
In the same way that a web browser reading HTML doesn't recognize
<warning>, neither would an XSL-FO processor understand the same
construct. In both cases we create a new arrangement of the #PCDATA from
under <warning>. We would create a <div
style="font-weight:bold;color:red"> for a browser and, likewise, a
<block font-weight="bold" color="red"> for an XSL-FO processor. We are
expressing in formatting objects the intent of what we want to see on the page, not knowing
where we are on the page, or perhaps what the running indents may be. We don't control the
placement of every character, or line break, or page break, we are simply expressing the
intent of how we want the content to appear.
Without constraints on presentation width and length in a browser, it is quite
straightforward to simply use the <div> for the browser, but this is not
the case for the printed form. It is common when formatting something important, perhaps
safety related, not to let the warning's content break over a page boundary. The reader may
stop reading the warning's content when they reach the end of the physical page, perhaps
missing important warning information found on the following page.
There is no feedback loop from the XSL-FO processor back to the process transforming XML. It is not a tightly-bound transformation aware of the current point in formatting. There is no way to measure available space and make transformation decisions based on such a measurement. So because the content is spread out over multiple pages, the XSLT stylesheet writer has no idea where on which page the current formatting point is going to be, nor the height of the content of the warning. So it is impossible to know if it is necessary or not to introduce manually a page break in advance of the warning.
Accordingly, the XSL-FO vocabulary provides for expressing contingencies in the formatting
properties that the XSL-FO processor takes into account when laying content out on the page.
Adding a "keep" contingency to the construct <block font-weight="bold" color="red"
keep-together.within-page="always"> instructs the XSL-FO processor that it must
attempt to fit all of the child content within the page containing the current formatting
point. If that child content does not fit, the block is moved to the top of the next page. The
block's content is then added starting at the top of that following page, whether or not all
of the content fits on that following page. Another contingency can be added to halt with an
error if the block then overflows that following page.
The process of formatting is this determination of where the page breaks belong and what content areas belong on each page, what areas nest inside of other areas, and how each area is to appear on each page. The result of formatting is referred to in the specification as the area tree.
The XSL-FO processor then has to realize the area tree in some medium using the rendering process. Although the specification provides for rendering in an interactive medium on a screen, and also in a aural medium over speakers, such media renderings have never made it to market. All XSL-FO processors in the marketplace render the area tree in a paginated print medium as a visual process.
The rendering, itself, may be a multiple-step process, producing the final form through a staged expression of rendering through interpretation on a given medium. For example, the rendering may require production of another intermediate formatting language such as TeX. Rendering may directly produce a final-form page description language such as the Portable Document Format (PDF), or the Standard Page Description Language (International Standard ISO/IEC 10180). The physical final form would then be produced from the intermediate form or final page representation. Indeed, there could be many steps to obtain a final result, e.g.: XML to XSL-FO to TeX to PDF to paper.
Thankfully, it is not necessary to know all formatting objects to get effective rendered results. There are sufficient common-sense initial values for formatting properties that a stylesheet writer can quickly prototype their output and then finesse the details.
6. Typical XML publishing data flows
An XSL-FO processor can offer to engage both the transformation process and the formatting/rendering process in a single product package. The result of transformation is internal to the process, but there should be a way to serialize this result for diagnostic purposes. If the results are as expected, then there is no need to incur the burden of serializing the intermediate result tree.
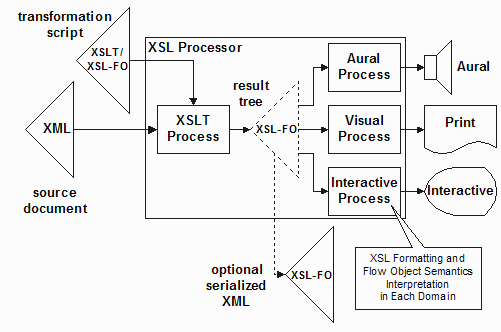
A more typical process deployed in the real world separates the transformation from the interpretation of the XSL-FO information reified as a standalone document. In this diagram, note that rendering is a small portion of the process of interpreting the XSL-FO. The bulk of the interpretation is the formatting to create the area tree to be rendered.
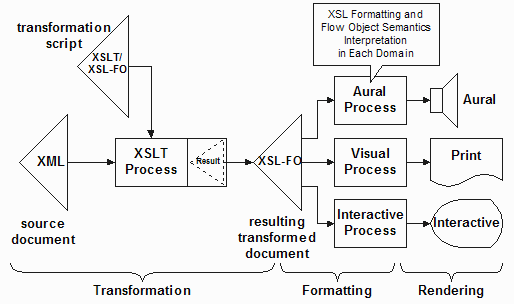
Noting now that XSL-FO is typically treated as a standalone XML document, there is no obligation to have used XSLT in the first place. In fact one can use XSL-FO simply as a paginated page production language for output from any application acting on your data. This diagram depicts from top down the history of using an arbitrary application to generate HTML, now XSLT to generate HTML, the sending of XML directly to an XML/XSLT user agent, the typical XSLT to generate XSL-FO and also the possibility to use any application to create XSL-FO.
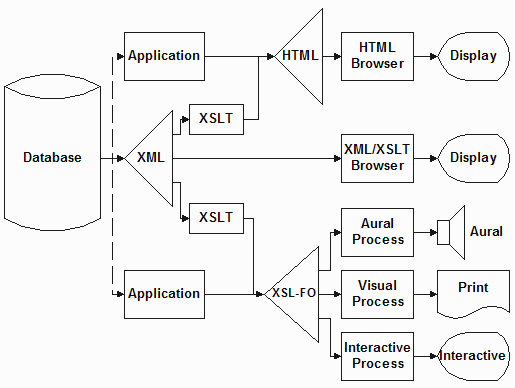
We need to remember that XSL-FO is just another XML vocabulary, requiring an application to interpret our intent for formatting in order to effect the result. This is no different than the use of the HTML vocabulary for a web browser.
7. Processing model of formatting
A quick look under the hood of an XSL-FO processor will help one plan what is needed in the XSL-FO instance to effect the result desired. I've included this because the recommendation is not a stylesheet writing guide, it is written for the XSL-FO processor implementer. It describes the processing model for XSL-FO as a series of formal steps in the derivation of the content to be rendered from the instance expressing the intent of formatting. The recommendation does not cover the creation of the XSL-FO instance, nor the detailed semantics of rendering, but focuses entirely on how to get from the former to the latter. But understanding this will guide one to understand how to quickly write the XSL-FO needed.
Although the processing model is described in the recommendation using constructs and procedural steps following a well-defined sequence, there is no obligation on a vendor that a particular implementation actually perform the steps as documented. The only obligation on a formatter is that it produce the rendered result as if it were implemented according to the steps described in the text. This nuance is important to vendors in that it allows them to implement any algorithm producing equivalent results, without constraining the innovation or flexibility to accomplish the results using any algorithm they wish. With this in mind, the theoretical steps to be implemented are as follows.
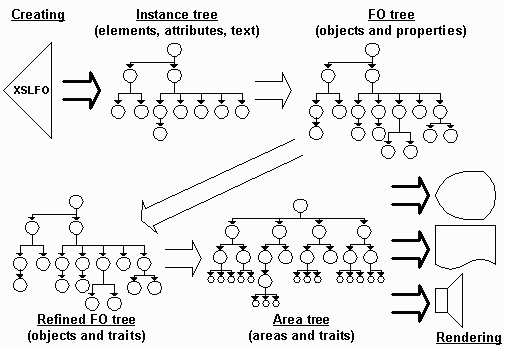
First, the instance of elements, attributes, and text becomes a tree of abstract nodes representing these constructs for processing. As shown earlier, it is possible that this node tree is passed directly from the result of transforming some source XML into result XSL-FO without instantiating the result as a file of markup characters.
This tree of elements, attributes, and text represents the expression of the intent of what the designer desires in the rendered result. This is called the Instance Tree and includes all of the content, including references to external foreign objects not expressible in XML, that is to appear in the target medium. It is the way the user expresses the interaction of the documented semantics described in the XSL-FO Recommendation.
The Instance Tree is interpreted into the Formatting Object Tree that is comprised entirely of formatting objects and their properties. This requires the (abstract) breaking of text nodes into sequences of character formatting objects, and the creation of properties from attributes.
The Formatting Object Tree is interpreted into the Refined Formatting Object Tree that is
comprised of objects and traits. Properties can specify two kinds of traits: formatting traits
(e.g. size and position) or rendering traits (e.g. style and appearance). Some property
specifications are shorthand expressions that encompass a number of separate trait
specifications and their values. Computed property expression values are evaluated and the
resulting values assigned to the traits. For example a property value of 2em when
the current font size is 20pt produces a trait value of 40pt. Once
all traits that are applicable to all formatting objects are determined, all traits not
applicable to each object are removed. At this point the information is comprised of all
objects that are used to create areas and each object has all the traits and only the traits
that are applicable to them.
The Refined Formatting Object Tree is interpreted according to XSL-FO semantics into the Area Tree that is comprised of areas and traits. A given object may create multiple areas at different branches of the Area Tree. Most objects produce exactly one area, and some objects do not produce any areas. Each area has a geometric position, z-layer position, content, background, padding and borders. Areas are nested in the tree within ancestral areas up to the highest (and largest) area which is the page area. Page areas are the children of the root node in the Area Tree. Page areas are ordered by their position in the Area Tree, but they are not geometrically related to each other in any way.
The rendering agent effects the impartation of the areas in the Area Tree according to the medium.
The rigor of the Recommendation language is necessary in order to ensure proper interpretation of finely-tuned typographical nuances. This makes the Recommendation difficult to read for many people just wanting to write stylesheets. Fortunately, simple things can be done simply once you get around the necessary verbosity of the Recommendation document.
The stylesheet writer addresses their specific publishing requirement in the reverse order of the processing model, first considering the desired layout. It is important to have clear requirements spelled out in advance of starting the writing task. Visual models of page geometry including headers, footers and margins should be drawn out. Details of content geometry including indents, lists, graphics and tables need to be spelled out in order to be prepared.
Working backwards, then, the stylesheet writer plans the general structure of the Area Tree of areas and traits that will render the specified results. Knowing XSL-FO constructs, the writer then enumerates which Refined Formatting Object Tree constructs are going to create the needed areas and traits. Considering the inheritance of traits from properties, the writer then strategizes where property specifications are best applied in the Formatting Object Tree that is created from the elements and attributes of the Instance Tree of the XSL-FO. This should then give the stylesheet writer clear guidance regarding the transformation of the source XML into the XSL-FO that will successfully produce the result.
8. Brief code examples
Consider the customer information expressed in XML as <customer
id="cust123">. A web user agent doesn't know how to render an XML element
<customer>. The HTML vocabulary used to render the customer
information could be as follows:
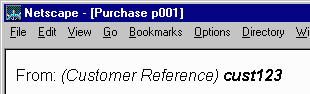
01 <p>From: <i>(Customer Reference) <b>cust123</b></i> 02 </p>
An XSLT creating HTML from the XML would produce the desired markup and the rendering result would then be as follows, with the rendering user agent interpreting the markup for italics and boldface presentation semantics:
Consider the same scenario for print. An XSL-FO rendering agent also doesn't know how to
render an XML element named <customer>. The XSL-FO vocabulary used to render
the customer information could be as follows:
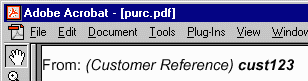
01 <fo:block space-before.optimum="20pt" font-size="20pt">From: 02 <fo:inline font-style="italic">(Customer Reference) 03 <fo:inline font-weight="bold">cust123</fo:inline> 04 </fo:inline> 05 </fo:block>
The rendering result when using the Portable Document Format (PDF) would then be as follows, with an intermediate PDF generation step interpreting the XSL-FO markup for italics and boldface presentation semantics.
Next, consider a simple, but complete, XSL-FO instance for an A4 page report:
01 <?xml version="1.0" encoding="UTF-8"?> 02 <root xmlns="http://www.w3.org/1999/XSL/Format" 03 font-size="16pt"> 04 <layout-master-set> 05 <simple-page-master 06 margin-right="15mm" margin-left="15mm" 07 margin-bottom="15mm" margin-top="15mm" 08 page-width="210mm" page-height="297mm" 09 master-name="bookpage"> 10 <region-body region-name="bookpage-body" 11 margin-bottom="5mm" margin-top="5mm" /> 12 </simple-page-master> 13 </layout-master-set> 14 <page-sequence master-reference="bookpage"> 15 <title>Hello world example</title> 16 <flow flow-name="bookpage-body"> 17 <block>Hello XSL-FO!</block> 18 </flow> 19 </page-sequence> 20 </root>
We can see the definition on line 2 of the default namespace being the XSL-FO namespace,
thus un-prefixed element names refer to element types in the XSL-FO vocabulary. Here there are
no prefixed element types used by any of the elements, thus the entire content is written in
XSL-FO. Many users choose to use the fo: namespace prefix, but there is no
such obligation to do so.
The document model for XSL-FO dictates the page geometries be summarized in
<layout-master-set> on lines 4 through 13, followed by the content to be
paginated in a sequence of pages in <page-sequence> on lines 14 through 19.
The instance conforms to this and conveys our formatting intent to the formatter. The
formatter needs to know the geometry of the pages being created and the content belonging on
those pages. Note, again, that the content is a sequence of pages and not individual
pages.
Think of the parallel where we learned the document model for HTML requires the metadata
in the <head> element and the displayable content in the
<body> element. Both elements are required in the document model, the first
to contain the mandatory title of the page and the second to contain the rendered information.
However we learned the vocabulary for HTML, when we create a page we know where the required
components belong in the document. The same is true for XSL-FO, in that we learn what
information is required where and we express what we need in the constructs the formatter
expects.
In this simple example the dimensions of A4 paper are given in a portrait orientation on line 8. Margins are specified on lines 6 and 7 to constrain the main body of the page within the page boundaries. That body region itself, described on lines 10 and 11, has margins to constrain its content, and is named so that it can be referenced from within a sequence of pages.
The sequence of pages in this example refers to the only geometry available and specifies on line 16 that the flow of paginated content is targeted to the body region on each page. The sequence is also titled on line 15, which is used by rendering agents choosing to expose the title outside the canvas for the content.
Consider two conforming XSL-FO processors to process this example, one interactively through a GUI window interface, and the other producing a final-form representation of the page:
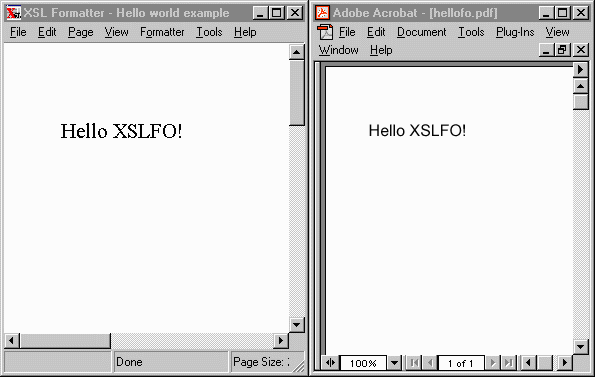
Note how the two renderings are not identical. The fonts are different. But the XSL-FO we used says nothing about fonts. If the XSL-FO instance is insufficient in describing the entire intent of the formatting, the rendering may engage certain property values of its own choosing. Page fidelity is not guaranteed if the instance does not express the entire intent of formatting. Yet even within the expressiveness of the XSL-FO semantics, there are some decisions still left up to the formatting tool. As mentioned before, this leads to different renderings of the same document by different vendors regardless of how detailed the stylesheet writer is in their work.
But this is not different than two web browsers with different user settings for the displayed font. A simple web page that does not use CSS stylesheets for font settings relies on the browser's tool options for the displayed font choice. The intent of the web page may be to render "a paragraph", but if two users have different tool option defaults for the font choice, there is no fidelity in the web page between the two renditions if the formatting intent is absent.
Let's consider finally a more complex formatting requirement, starting with the desired page layout of a page from a book of training material. On this page there is a graphic, a horizontal rule, some text in a serif font that is flowed in a list and some text, in two sizes, that is rendered in a monospace font without flowing.
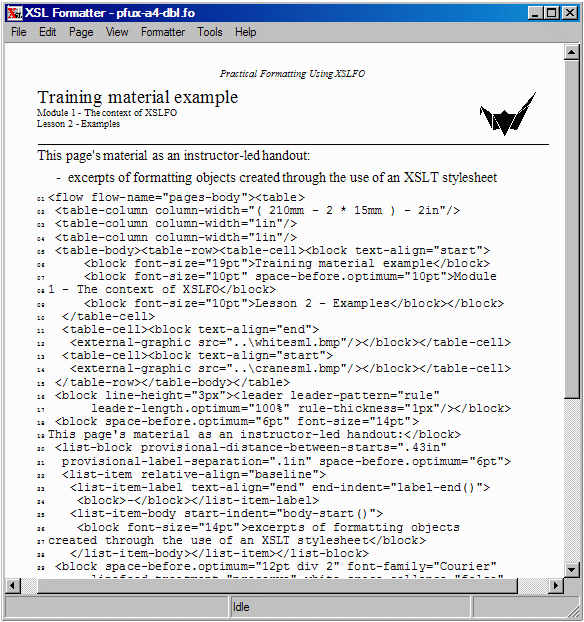
Determining the XSL-FO constructs required for layout, we can put the information above the horizontal rule into a borderless table. The nesting of the hierarchy of the formatting objects would then be as follows.
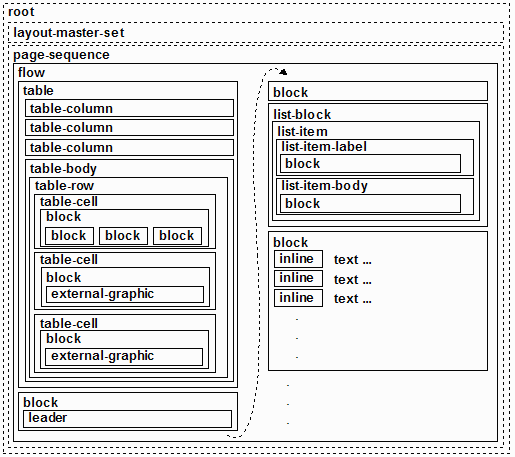
This leads us to express the information as the following XSL-FO elements and attributes, strategically placing property specifications where inheritance will apply them to descendant formatting objects.
01 <flow flow-name="pages-body"><table> 02 <table-column column-width="( 210mm - 2 * 15mm ) - 2in"/> 03 <table-column column-width="1in"/> 04 <table-column column-width="1in"/> 05 <table-body><table-row><table-cell><block text-align="start"> 06 <block font-size="19pt">Training material example</block> 07 <block font-size="10pt" space-before.optimum="10pt">Module 08 1 - The context of XSL-FO</block> 09 <block font-size="10pt">Lesson 2 - Examples</block></block> 10 </table-cell> 11 <table-cell><block text-align="end"> 12 <external-graphic src="..\whitesml.bmp"/></block></table-cell> 13 <table-cell><block text-align="start"> 14 <external-graphic src="..\cranesml.bmp"/></block></table-cell> 15 </table-row></table-body></table> 16 <block line-height="3px"><leader leader-pattern="rule" 17 leader-length.optimum="100%" rule-thickness="1px"/></block> 18 <block space-before.optimum="6pt" font-size="14pt"> 19 This page's material as an instructor-led handout:</block> 20 <list-block provisional-distance-between-starts=".43in" 21 provisional-label-separation=".1in" space-before.optimum="6pt"> 22 <list-item relative-align="baseline"> 23 <list-item-label text-align="end" end-indent="label-end()"> 24 <block>-</block></list-item-label> 25 <list-item-body start-indent="body-start()"> 26 <block font-size="14pt">excerpts of formatting objects 27 created through the use of an XSLT stylesheet</block> 28 </list-item-body></list-item></list-block> 29 <block space-before.optimum="12pt div 2" font-family="Courier" 30 linefeed-treatment="preserve" white-space-collapse="false" 31 white-space-treatment="preserve" font-size="12pt"><inline 32 font-size="inherited-property-value(font-size) div 2">01 </inline 33 ><flow flow-name="pages-body"><table> 34 <inline font-size="inherited-property-value(font-size) div 2" 35 >02 </inline> <table-column column-width...
Lines 1 through 15 describe the three columns of information in the borderless table: the page title and context, a placebo white box in place of the branding logo for the licensee of the training material, and the Crane registered trademark. The table cell with the page information contains text in different point sizes on lines 6 through 9.
Note how attribute value specified on line 2 is an expression, not a hard value. There is an expression language in XSL-FO that is a superset of the expression language of XSLT. This can make an XSLT stylesheet easier to write by having it convey property values in a piecemeal fashion in an expression to be evaluated, rather than trying to calculate the resulting value in XSLT.
The horizontal rule below the title information needs to be block-oriented in that it needs to break the flow of information and be separate from the surrounding information. To achieve this effect with the inline-oriented leader construct, note on lines 16 and 17 how the leader is placed inside of a block. Note also how the line height of the block is adjusted in order to get the desired spacing around the leader.
The block on lines 18 and 19 lay out a simple paragraph.
Lines 20 through 28 lay out a list construct, where the labels and bodies of list items are synchronized and layout out adjacent to each other in the flow of information. This side-by-side effect cannot be achieved with simple paragraphs, and could be achieved to some extent with borderless tables, but the use of the list objects gives fine control over the nuances of the layout of a list construct.
The list block itself has properties on lines 20 and 21 governing all members of the list, including the provisional distance between the start edges of the list item label and the list item body, and the provisional label separation. These provisional values are very powerful constructs in XSL-FO. They allow us to specify contingent behavior for the XSL-FO processor to accommodate the varying lengths of the list item labels of the items of the list.
Note
Remember one of the design goals of XML was that "terseness is of minimal importance" (could they have found a terser way of saying that?). Note how the attribute name specifying the first of these provisional property values is 35 characters long. It is not uncommon to need to use lengthy element and attribute names, and an XSL-FO instance always seems to me to be so very verbose to read.
Note on lines 23 and 25 how functions can be used in attribute values. XSL-FO defines a
library of functions that can be invoked in the expression language. The
label-end() and body-start() functions engage the appropriate use
of one of the two provisional list construct properties based on the length of the item's
label. This illustrates how XSL-FO can offload layout decisions from the XSLT stylesheet,
especially when it would be impossible for the XSLT stylesheet to know precise placement
details that are effected by font and other issues being tracked by the formatting
process.
Line 29 begins the block containing the listing of markup. To ensure a verbatim rendering of edited text, line 30 specifies that all linefeeds in the block of content be preserved, and not to collapse the white-space characters. This disengages the default behavior of treating linefeeds as white-space and collapsing white-space to a single space character, as would be typical for proportional-font paragraphs of prose.
Lines 31 and 32 show an inline sequence of text being formatted differently than the
remainder of the text of the block. The desired effect of the line number being half the
current font size is specified through the use of the function
"inherited-property-value(font-size)", though there are two alternate ways of
specifying the same relative value: "50%" and ".5em". Using any of
these expressions would both produce the same result.
The escaped markup on lines 33 and 35 may look incorrect, but this is an XML serialization of the XSL-FO instance, hence, sensitive markup characters must be escaped in order to be recognized as text, and not as markup. Since this is a page describing markup, the markup being described needs to be distinguished from the markup of the document itself.
9. Conclusion
Accepting that HTML and CSS are suitable and sufficient for browser-oriented rendering of information, the W3C set out to define a collection of pagination semantics for print-oriented rendering. These pagination semantics are equally suitable for an electronic display of fixed-size folios of information, such as page-turner browsers and PDF readers.
The Extensible Stylesheet Language (XSL), also known colloquially in our community as the Extensible Stylesheet Language Formatting Objects (XSL-FO), combines the heritage of web and SGML technologies in a well-thought-out and robust specification of formatting semantics for composing and paginating information.
The Recommendation itself is a rigorous, lengthy, and involved technical specification of the processes and operations engaged by a formatting processor to effect consistent paginated results compared to other formatting processors acting on the same inputs. Well-written for its intended purpose, the W3C document remains out of reach for many people who just want to write stylesheets and print their information.
Nevertheless, simple things can be done simply, and new users to XSL-FO can build up their experience to create professional-looking results with nuanced page composition features to meet demanding requirements for print quality and fidelity with web presentations.